July 9, 2023
AWS Reserved Instances - How Much Can You Really Save?
Consider all the various discounts AWS offers to maximize savings and mitigate the risk of overcommitment.
Streaming pipelines on AWS can be expensive. Here’s how we cut AWS costs 67% without reserved instances or savings plans

Louis-Victor Jadavji (or "LV") is a recognized leader in the cloud services industry. He's helped 50+ digital native companies like ModusBox, Later, and NS1 choose the right cloud stack for their applications. His work has been featured in Forbes (30 Under 30 All-Star), HuffPost, The New York Times, The Globe and Mail, and Inc. Magazine.
.jpg)
At Taloflow, we are determined not to be the cobbler whose children went barefoot. We approach our own AWS costs as if we are helping one of our customers. The results are striking and worth sharing. And, with zero upfront or reserved commitments required!
This post illustrates how a little bit of diligence and a clear cost objective can end up making a large impact on profitability.
At Taloflow our main deployments involve:
To accomplish this in the past we used:
The first "major key" 🔑 to managing costs is some sort of cost monitoring platform that makes it easy to communicate cost objectives to developers. This should provide easy visibility into the various cost factors. Some form of alerting for detecting adverse changes fast also helps a lot. Luckily, we knew where to find one of those.
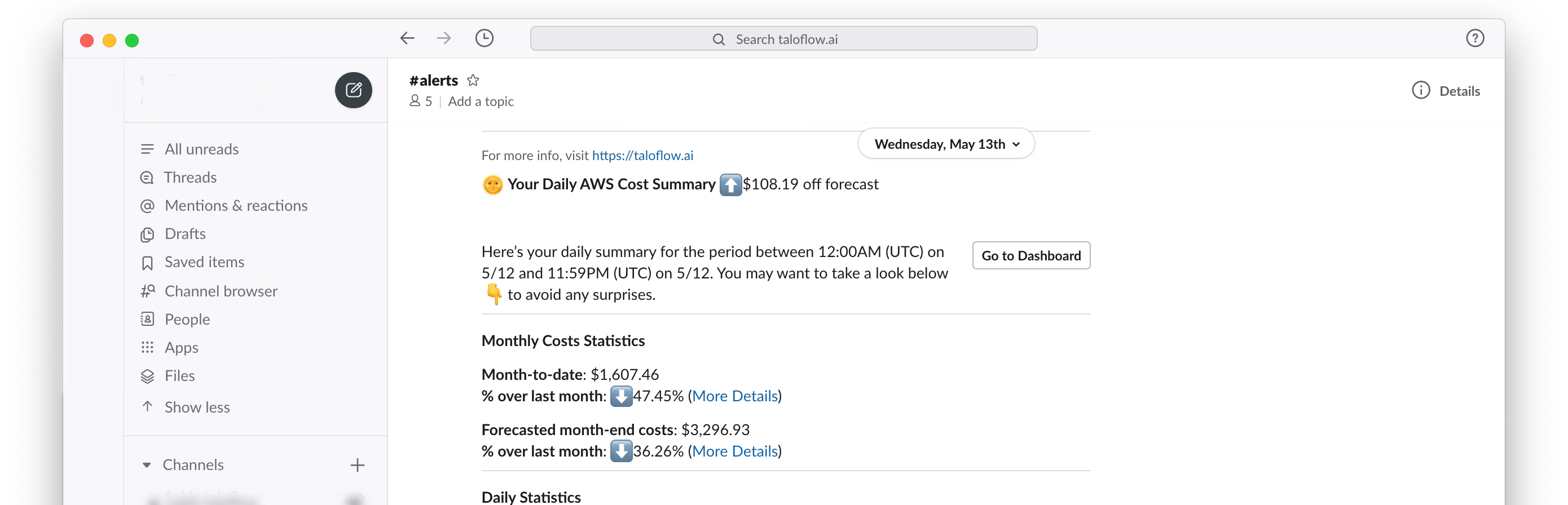
Also key was some way to correlate user activity on our platform to our AWS costs (i.e.: marginal analysis of cloud spend). This allows us to track efficiency without the quantity variance. If our bill goes up 20%, we know whether it’s due to engineering inefficiency, architecture or product changes, or even an increase in business demand.
The goal was to provide the services that our customers wanted, but at the optimal marginal and average cloud cost point on our side. This means tracking units of work or activities (e.g.: number of customers, API calls, reports generated) and relating them to the services we provide. We can then determine how changes in costs are also related to changes in these activities. Below are the two that we track very closely.
We figured out that our expenses with some services were a lot higher as a percent of the bill than others. We needed to make some minor and major adjustments to our infrastructure and code to deal with this. Because...credits were running out 🕚. In order, the most expensive services were: AWS Glue, Amazon EC2, Amazon S3 and Amazon MSK.

Of course our changes are specific to our use case, but we emphasized the approach in this post. The key is for you to focus on your lowest hanging fruit first, and gradually move to smaller but growing AWS costs. In our case, this is what we did in the following order:
The project produced the following results:
This is rarely easy. The complexity of this task will depend on the size of your company and how many people are allowed to create EC2 instances. Some have gatekeepers, some don't. One might need to ask other people if, for some reason, they are still using some instances that appear useless. We know, chasing people sucks. 🤦🏽Good tagging may help find undesired yet still live instances.
P.S.: If you don’t tag anything, it’s never too late to start doing that. A bit of extra effort will help the next time you have to trim cloud costs.

Creating some S3 lifecycle policies helps to find and delete unnecessary files. When a part of your service processes some files, and you also have some partially processed files, it’s easy to accumulate lots of them. Defining policies to delete or change the storage class of the respective files can make a big difference.
We resized our jobs to run without AWS Glue. They were “dockerized” and run as Amazon ECS tasks on AWS Fargate. We refactored our Glue Jobs to require less memory and to run in smaller chunks. This enabled us to move much of that work to Fargate, which cost us 1/3 of what the Glue runs had cost.

Instead of using AWS Athena queries, we reduced the amount of data needed to crawl the databases by pulling it directly from S3. (with filtered pulls) This allowed us to optimize the amount of GetObject requests which were starting to become a big headache. In addition, it drastically reduced the amount of crawling needed to keep the partitions updated for the data pulls.
We converted our AWS Glue job responsible for converting a huge CSV into de-duplicated parquet files into an Apache Flink pipeline job. We were already running Flink inside an EMR cluster. So we simply introduced a new Flink job with the same functionality of that AWS Glue job. In essence, our Flink pipeline was a sunk cost we had incurred. We decided to use it and avoid incurring the marginal costs from the use of the AWS Glue pipeline, which is charged hourly.
While we implemented the new Flink job to replace the AWS Glue job, we changed the size of the parquet files being generated. Our Glue job was creating an insane amount of small files in one of our S3 buckets. This in turn caused AWS S3 GET and PUT operations to go higher and increase our AWS bill significantly.
.svg)
The first version of our platform made heavy use of Apache Kafka. It was crucial to have a robust and stable Kafka cluster running all the time. But, with some of our past changes (before these adjustments), our use of Kafka became much less demanding. Although our expenses with MSK were pretty fixed, we were not that dependent on Kafka anymore, so using MSK was not cost efficient. We were able to move our Kafka to ECS and run it as a containerized group. We didn’t need some of the redundancies after all.
We dramatically reduced our active logging, while making sure it could be re-enabled for debugging purposes. This is an interesting cost to monitor in that it creeps up quickly. It's easy for developers to throw in debugging logging without a plan as to how that logging will be utilized in production. The net result is not only potential security violations, (oops!) but unnecessary costs. We believe that production logging and development logging should have different requirements. We know not to log everything the same way.
.svg)
We used to have 2 EMR clusters on each environment and used on-demand instance groups for every node type (Master, Core, or Task).
First, we made some tests using instance fleets with spot instances. We enabled the switch to on-demand instances if a provisioning timeout happened, but that didn’t work. Here's why...
Our clusters could provision all the instances while it started. But, if AWS reclaimed all of our instances in a given fleet (Core or Master), the cluster crashed! They didn’t switch to on-demand and resizing the fleet to use an on-demand instance or a different number of spot instances changed nothing.
To solve this, we turned our 2 EMR clusters into a single cluster. We kept using an on-demand instance as the Master node and another as part of the Core nodes. All of the other Core or Task nodes as Spot instances. The failure rate of this implementation is low. However, AWS can reclaim an instance at anytime, which can cause some of the steps to fail. To that end, it’s important to have a certain level of fault tolerance to deal with that. In our case, we implemented a simple retry mechanism to re-run the failed steps. It worked.
After these adjustments were all made, we could wonder at the results. Again, this was the difference:
These changes represent a nearly 67% reduction of our monthly AWS bill. 😺We didn’t even need commit to any new savings plans or reserved instances. (That could save us even more money, but we'll leave that for another post). It is also exciting to see that we improved our marginal cost per customer, which is a key SaaS metric! We know that some of our success is use-case specific. However, the direction we took can be applied to save money for any AWS user. We invite you to email us with any questions: [email protected]
Here are some more posts from Taloflow and its community that are related to this topic.
Get a transparent client-ready report tailored to your client's unique use case and requirements.

