March 17, 2022
Why just one person can't buy things that work well
This post covers Taloflow's thesis as to why just one person can't buy things that work well for every kind of thing.
This post covers Taloflow's thesis as to why just one person can't buy things that work well for every kind of thing.

Louis-Victor Jadavji (or "LV") is a recognized leader in the cloud services industry. He's helped 50+ digital native companies like ModusBox, Later, and NS1 choose the right cloud stack for their applications. His work has been featured in Forbes (30 Under 30 All-Star), HuffPost, The New York Times, The Globe and Mail, and Inc. Magazine.

It's too difficult for product teams to find the right vendors. Vendors obscure details, promise everything or downright lie, have special pricing for those who know how to ask, and there are just too many of them!
This problem is getting worse because of the "Cambrian explosion" in cloud tooling, a blossoming in the number of solutions and niche specializations.
It's a problem that resonates in the ranks of virtually every product-first company I meet with (this HN thread also illustrates how common it is). How many more months of precious engineering time will we waste building massive spreadsheet matrices, debating use case fit internally to figure out what matters, and pouring through developer documentation?
This post:
I wanted to find a suitable email marketing API for our company's use case a while ago. A fellow entrepreneur sent me a matrix of vendor functionality he found through a startup studio (Venture Harbour).
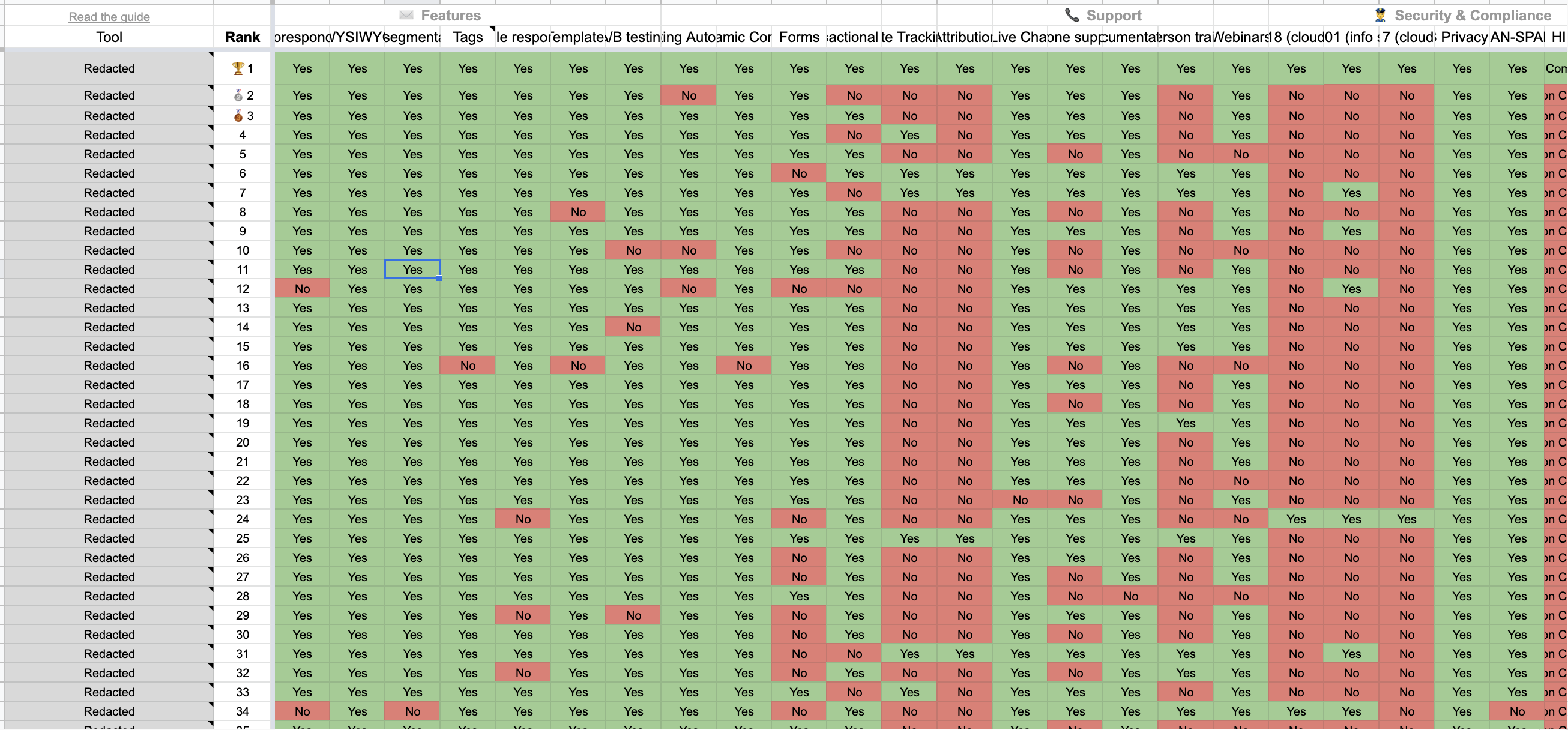
I had to spend roughly 30 more hours before I was ready to make a decision:
Low and behold, I still made the wrong decision. Two months later, our team had to switch to another vendor despite the pain of integrating everything all over again.
Several senior architects have shown me the pain-staking exercise they go through when compiling complex spreadsheets (like the one above) for their next buying decision. Sometimes they get it right, but as Dan Luu notes, this often goes wrong.
What I needed was an expert analysis tailored to my use case. But unfortunately, I didn't have the time to run the analysis, nor am I an expert in email marketing APIs. Besides, why should I be forced to invest the time into becoming an expert for what should be a one-time decision?
What if what we learned from the failed spreadsheet experiment was fixed? Can we find a way to:
Surely, there's a market for this, right?
Below, we cover the four main steps we take to do it and the potential problems with our model.
In the abstract, the expert's role is to build the matrix of vendor functionality and possible points of differentiation, group features into dimensions, and weight these dimensions based on their understanding of the use case. It's what industry analysts and consultants at companies like Gartner, Deloitte, or specialty firms, do all day. There is a risk to engaging them: consultants and analysts possibly are expensive, unskilled (and you might not be able to tell), have secretive methodologies, and even conflicts of interest.
However, providing an expert system that encodes a matrix of vendor functionality, asks relevant questions, and provides recommendations based on unique needs, can help most people make better decisions. That is, as long as we execute the following:
Some things are an explicit "Yes" or "No" when building matrices. For example, our Observability experts can rate Instana as best-in-class for "Visible Metrics in <1 Second" (it's the only one that has it) and New Relic as unavailable for "Language Independent Agent with Dynamic Instrumentation" without giving it too much thought. However, vendor support for "Continuous Profiling (Capture Code Profile for Every Trace/Transaction)" is more nuanced, and that's where the expert and a gradient for rating vendors against any given feature is vital. We can take multiple expert opinions and normalize the ratings in such cases.
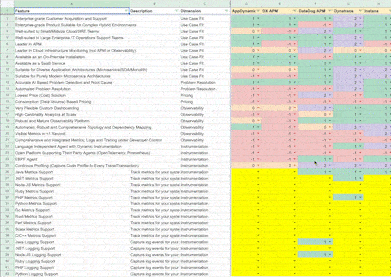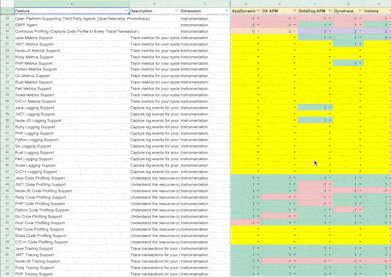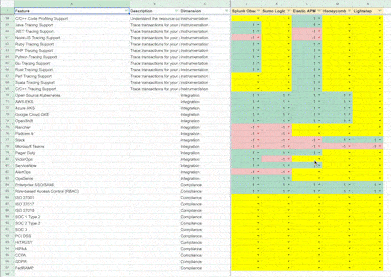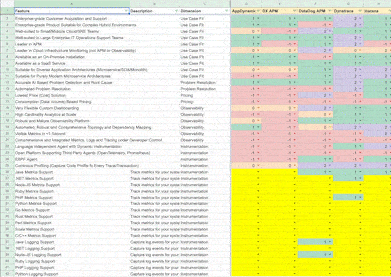
Features are constantly changing, and service levels improve and worsen too. Without a robust system to monitor these changes, any system will quickly go out of date. Given the feature velocity in IaaS and PaaS, I believe the cycle for refreshes should be within two weeks. Tools like VisualPing can check pricing pages and documentation in short intervals for any changes. Category-focussed analysts can then triage and extract the relevant information based on their general knowledge of the category and update matrices accordingly.
There are multiple options for monetization, and frankly, we're exploring several.
Here are some quick ones:
What if the AWS affiliates that clog up Google's search results only got paid if you used that toaster oven for the next five years? That's the kind of model we think it takes to incentivize accurate recommendations. Specifically, an affiliate-style system that only pays out if a company sticks for a certain amount of time and is paid out over the course of a few years. However, you have to include a comprehensive group of vendors in the analysis, no matter the referral relationship. If AWS won't pay for a referral, what good would an object storage recommendation be if it didn't include Amazon S3 in the analysis?
The idea is to upsell mid-market and enterprise customers on a collaborative decision-making workflow. The compendium of reports can become an enterprise record system for the "Why?" behind buying decisions. For example, have you ever wondered why the Director of Engineering who left your company several quarters ago made a particular vendor decision? Now, you can look it up and benefit from the same analysis or start anew.
How do we avoid asking users about the importance of each feature? There are hundreds of table-stake features, and even after distilling to the actual points of differentiation, you're usually still left with 100-200 features to evaluate against a typical use case. That would make for one of the most tedious intake forms ever.
The goal is to get users the relevant information to build conviction in five minutes:
A similar thing can be done for other products, like DSLRs. For example, suppose you're a wildlife photographer. In that case, you're going to prioritize systems with high-quality long-distance zooms and are likely to prefer a system with some level of weather-sealing.
This process is not specific to cloud tooling. We chose cloud services because we previously were a cloud cost optimization platform before our pivot.
Thanks to the model described in Steps 1 through 4, your use case-specific needs are weighed individually, and the final result is a ranked set of vendors and their properties (including gotchas) for your use case. You can then make an informed purchasing decision.
Most similar-looking products are dramatically worse. It's a common marketing strategy to throw a fake quiz before a quote. Take car insurance, for example. It's pervasive to see lengthy quizzes that end with a form that asks for your name and number, which is then sold to vendors that will spam call you for weeks.
There's negative value created, and the public perception of "answer these questions for a recommendation" tends to be very poor.
It's challenging to communicate to potential users that you will:
Can't you talk to peers in your industry and do precisely what the smartest ones do? That seems to be the approach of platforms like G2 and many Slack communities organized around specific functions, like marketing, data science, or DevOps. That sometimes works, mainly for SaaS products. You can possibly figure out whether to use Slack or Mattermost based on a handful of valued peer opinions. However, when it comes to software used to make software (i.e., developer and cloud tooling, or IaaS and PaaS), it's almost always cloudier (pun intended), and the new model we described is more necessary.
Why is it cloudier than SaaS? Primarily, it's because the quality of the product experience for IaaS and PaaS varies much more between use cases. Underlying this are more complex offerings with hundreds of points of differentiation and more than a handful of dimensions that should be considered when making a decision. As an example, here's a shortlist of the dimensions we studied for Observability tooling:
G2 will not complete the last "selection" mile in the buyer's journey when choosing between Dynatrace, Splunk Observability, and the like. However, we think our new model can.
Here are some more posts from Taloflow and its community that are related to this topic.
Get a transparent client-ready report tailored to your client's unique use case and requirements.

