
October 2, 2023
How to Choose the Best SMS API in 2024
An in-depth review of what an SMS API is, its benefits over email communication, and the key questions you’ll want to consider before choosing an SMS platform.
What exactly is object storage and how does it differ from block storage?

At Taloflow we recently launched a way for companies migrating from AWS/GCP/Azure to 3rd party object storage providers like Storj to receive an objective TCO analysis of all the switching and storing costs associated.
But what exactly is object storage - and how does it compare to block storage? For both, we will cover the technical description, benefits, and application use-cases. We will then investigate the pricing differences and draw comparisons between the two, allowing you to choose the correct option for your use case.
As more and more processes become digital or digital-first, the amount of data stored in the world continues to increase. In 1990 (and before the cloud) 1 gigabyte of storage roughly cost $10,000. Today you could blink and accidentally transmit and store 1 gigabyte worth of metadata in the cloud.
Some trends we continue to observe:
Block storage has been used for many years and is simple and familiar. Block storage providers allow a block storage device to be provisioned to any size and attached to virtual machines with ease. On-premises storage like SAN, iSCSI, and local disks are all examples of block storage.
Block storage is treated like any other system disk. It can be formatted with a filesystem, used to store files, or used as a database backend. Block storage can be directly written to by nearly any application.
Block storage is called such because each unit is a separate piece of the file, identified with a unique id. There’s no metadata associated with each block and because data is split in this way, performance is better when block storage and applications are closer together.
With the rise of cloud computing, block storage can now be purchased from AWS Elastic Block Storage, Rackspace Cloud Block Storage, Azure Premium storage, and many more.
Familiarity
Block storage is familiar to developers and applications. It’s been the old paradigm and will continue to be used for mounting disks to servers. It’s the most commonly used storage type for most applications.
Performance
Block storage is reliable and fits right in with applications that require a high number of IOPS and low latency. Database servers and analytic-heavy workloads are two areas where block storage shines. Object storage, in comparison, doesn’t do so well here and shouldn’t be used for data-heavy applications.
Flexibility
Adding block storage volumes is simple and has few performance impacts. Block storage can also be imaged and moved fairly easily between servers. Modifying files is also much more flexible than object storage. Individual blocks can be modified, rather than the entire file as with object storage.
Data management
Though block storage is flexible, it still requires much more administration and hands-on work than object storage. Decisions on permissions, versioning, and backups must all be given consideration. Block storage requires much more management at the operating system level, whereas object storage abstracts that all away for you.
Server binding
Block storage is tied to a single server at any one time. Contrasted this with object storage, which can be accessed over an API from anywhere.
No Metadata
Block storage metadata is limited to basic file attributes, whereas object storage can tag objects with metadata that makes search and retrieval easier.
Cost
By its nature, block storage is much more expensive than object storage. If you allocate block storage space, you’ll be paying for it, even if you aren’t using it. With object storage, you only pay for what you use.
Block storage does well for applications that need a physical disk to write data to. Ideal use-cases include:
Cloud Object Storage is much newer than block storage. It manages data as -- get this -- objects! These objects are stored in a flat address space, in contrast with block storage’s more hierarchical structure. Objects could be anything, server logs, images, Html source code, or any “blob” of bytes.
Each object contains the data itself, metadata about the data, and a unique global identifier that enables distributed systems and apps to locate the data. This key distinction of metadata is also one of object storage’s advantages.
Consider songs stored in object storage. The metadata can describe the band name, year recorded, instruments used, lyrics, and much more. Block storage, on the other hand, really is limited to basic file attributes. With metadata, data can be searched much more easily than block storage.
Amazon S3 is probably the most well-known Cloud Object Storage provider. Alternatives like Azure Blob Storage, Google Cloud Storage, and DigitalOcean Spaces all offer Cloud Object Storage services.
Scalability
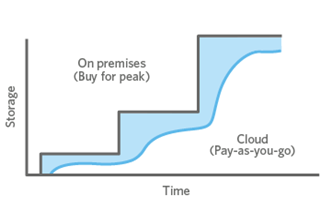
One of the biggest benefits of Object Storage is its ability to scale, providing a level of elasticity that traditional methods cannot provide. The amount of storage required has no physical restrictions like block storage does, allowing organizations to only pay for the data storage they use. Applications seeing large amounts of user-generated data would be wise to consider using cloud object storage. Block storage costs money whether you’re using the entire allocated storage space or not.
Availability & Durability
Cloud Object Storage providers are well established and operate thousands of geo-distributed data centers. Availability and durability are in the best interests of these providers. AWS, for example, automatically distributes data “across a minimum of three physical facilities that are geographically separated by at least 10 kilometers within an AWS region”. Service Level Agreements are typically above the “five nines” of high availability. This data-resiliency is usually built-in, compared to block storage, which may require more administration.
Simple Data Management
Cloud Object Storage is usually uploaded and modified via a simple HTTP API. Clients exist for nearly all major Operating Systems and programming languages, making integration with Cloud Object storage providers super simple. Many cloud providers offer built-in CDN integration, which can help reduce page load times for users. Object storage services also greatly simplify data management, meaning you won’t need to set up a RAID array or maintain individual disks at the Operating System level.
No ability to edit one part of a file
Object storage will not allow you to edit one part of a file, unlike block storage. Objects are complete units and can only be edited as such. This could have negative performance impacts if objects are large or need frequent modification. Consider a server log file that requires appending a line for each event it logs. With object storage, you’ll need to save the object, append the new line, and rewrite the entire object back. Object storage is not ideal for data that changes frequently.
Ease of access
Operating systems can directly access block storage as a direct-attached disk, but this is not the case with object storage. There are workarounds to mount object storage, but performance is going to suffer.
High Latency
Object storage isn’t a very good fit for backing a database, due to its high latency and frequent access over API. Block storage is a much better use case for these types of applications.
Cloud Object Storage excels at saving any kind of static data that is quickly increasing.
Choosing between Cloud Object Storage and Block Storage can be a complex decision, even for seasoned developers. Object Storage and Block Storage each have their distinct advantages and tradeoffs. Hopefully, you’ve gained some understanding of those use-cases and tradeoffs that will allow for building more scalable and reliable technology. If you need help with deciding between the best object storage vendors for you, don't hesitate to contact me at [email protected]
It takes five minutes to get your free, accurate recommendation
Get my free recommendation
Here are some more posts from Taloflow and its community that are related to this topic.
Get a transparent client-ready report tailored to your client's unique use case and requirements.

