An In-Depth Guide to Data Labeling - Tools, Best Practices & More
Understand everything you need to know about data labeling and how to select the best tools for your use case.
Louis-Victor Jadavji, Cofounder of Taloflow
Louis-Victor Jadavji (or "LV") is a recognized leader in the cloud services industry. He's helped 50+ digital native companies like ModusBox, Later, and NS1 choose the right cloud stack for their applications. His work has been featured in Forbes (30 Under 30 All-Star), HuffPost, The New York Times, The Globe and Mail, and Inc. Magazine.
Artificial intelligence (AI) drives innovations across all facets of our lives, from self-driving cars to email spam filtering to personalized shopping to smart homes and automated investing. There's no denying that these critical innovations wouldn’t have been possible without today’s businesses’ impressive data gathering capabilities. But perhaps more important is the ability to train AI tools using the data.
Machine learning models can’t rely on raw data to make the complex estimations and decisions we've come to expect of AI algorithms today. Data has to be labeled or annotated in a manner the computer will understand to make it actionable. Choosing the right data labeling platform is challenging because vendors rarely publish pricing and their true capabilities to support AI projects are mostly unknown. Worse yet, you may not even own the data that you give them.
In this guide, we address:
👉 What data labeling is and how to know if you've got a good vendor
👉 The most common mistakes made when choosing a data labeling provider
👉 The recommended vendors for specific use cases
What is Data Labeling?
Data labeling is the process of adding labels or tags to raw data in text, images, videos, audio files, etc. These labels help computers 'understand' the data, and they help train machine learning algorithms to make accurate estimations, predictions, or decisions.
How Does Data Labeling Work?
Different organizations may have varying approaches to data labeling, depending on the resources at hand and the volume of data they have to work with. Data labeling may be done in-house, outsourced, crowdsourced, or with the help of a data labeling tool. Below are some of the most critical steps in data labeling:
Quality Assurance
Quality assurance is an essential component of the data labeling process. For the machine learning model to work successfully, the labels on data need to reflect a ground truth level of accuracy, unique, independent, and informative. This holds for all machine learning applications, from building computer vision models to natural language processing.
QA ensures all labeled data meets these requirements. If you're labeling your data in-house, it's vital to have the necessary QA checks in place. In the same vein, any reputable data labeling service should have well-defined QA processes. Still, it's one of the factors you need to consider before committing to a contract with the service provider.
Train and Test
Once your labeled data has passed QA, the next step is to train your ML model using the data. The process typically involves testing the model on an unlabeled data set to see if it delivers the correct predictions or estimations. The confidence threshold or accuracy level you'll develop will depend on the application of the model.
For example, a model that helps self-driving cars detect stop signs and pedestrians should have a shallow margin for error, while a model that predicts similar products in an online store may have a higher margin.
Utilize Human-in-the-Loop (HITL)
Humans are an essential component of the data testing process because they provide ground truth monitoring. With HITL, you can confirm if your model is making the correct predictions or not. If the projections are not as accurate as you expect HITL, further helps you identify gaps in the labeled dataset and retrain as necessary.
What is Data Annotation?
Data annotation is often used interchangeably with data labeling, although this is frowned at in some industries or use cases. Data annotation refers to the data labeling process itself.
What is 'Human-in-the-Loop' (HITL)?
HITL is a branch of artificial intelligence that creates machine learning models by leveraging human and machine intelligence. The approach involves a continuous cycle of interactions between humans and machines to develop an algorithm that delivers the desired confidence threshold.
Typically, the loop starts with humans labeling the data. Next, the ML algorithm learns to make predictions from the labeled dataset. Afterward, humans tune the model, usually by scoring the data to give room for over lifting and teaching classifiers about new categories or edge cases. Finally, humans validate the model by assessing its predictions and verifying that they fit into the desired confidence threshold.
How To Scale Data Labeling
Data labeling is a time-consuming task. To get high-quality data and performance, you have to continually train and tune your models to match the volume and complexity of your data sets. While running this process in-house may be perfect if you're just starting, you're likely to get to a point where the outcome does not justify the time and effort expended.
For example, if your top data scientists and engineers have to devote time to labeling, it might be time to consider scaling with a data labeling service. Below are the most important steps to follow when scaling data labeling.
Design for workforce capacity
With the right data annotation service, you'll have access to a large pool of workers that can deliver high-quality data to suit your needs. Although crowdsourcing provides a cheaper alternative, research has shown that managed teams give better results on identical data labeling tasks.
So, your best bet is outsourcing to an expert data labeling service. It would be best if you also tried to stick with the same labeling team as much as possible because the quality of data delivered improves as they get more familiar with your requirements and edge cases.
Look for elasticity
It's vital to remember that the volume of unlabeled data you need to work with may change with time. That's why hiring an in-house labeling team may not be an intelligent decision. If you increase your in-house capacity due to a volume spike, would you still be able to afford them during periods of decreasing growth? The right data labeling service should be flexible enough to help you scale your labeling needs up or down as necessary.
Choose smart tooling
Your choice of data enrichment tool will also influence your scaling capacity. The important thing here is to leave room for growth. A company's data labeling requirements typically change over time. Thus, any tool you're choosing should leave room to make changes to your data features, labeling workflow, and labeling service provider. Many companies who build their labeling tools in-house will only find out about the rigidity of their software when it's too late.
Measure worker productivity
The workforce you're engaging for data labeling should also earn their buck. Generally, worker productivity is measured using these three criteria:
The volume of the data labeled
Quality of output
Worker engagement
If you're labeling data in-house, you can also devise other measures for tracking worker productivity. The point is to ensure that everyone on the labeling team contributes positively to the task and that the results are accurate enough for the intended purpose.
Streamline communication between your project and data labeling teams
There should be a close feedback loop between the data labeling team and the project team for best results. This gives both teams the agility to make immediate changes such as iterating data features or changing the labeling workflow. Because data labeling is often linked with the customer experience and product features, fast and seamless communication between the two teams is vital when scaling.
What is a Data Labeling Platform?
Data labeling platforms provide the toolset data annotators need to turn unlabeled data into the labeled or training data required to build AI algorithms. These tools facilitate collaboration between humans and machines to deliver high-quality outputs.
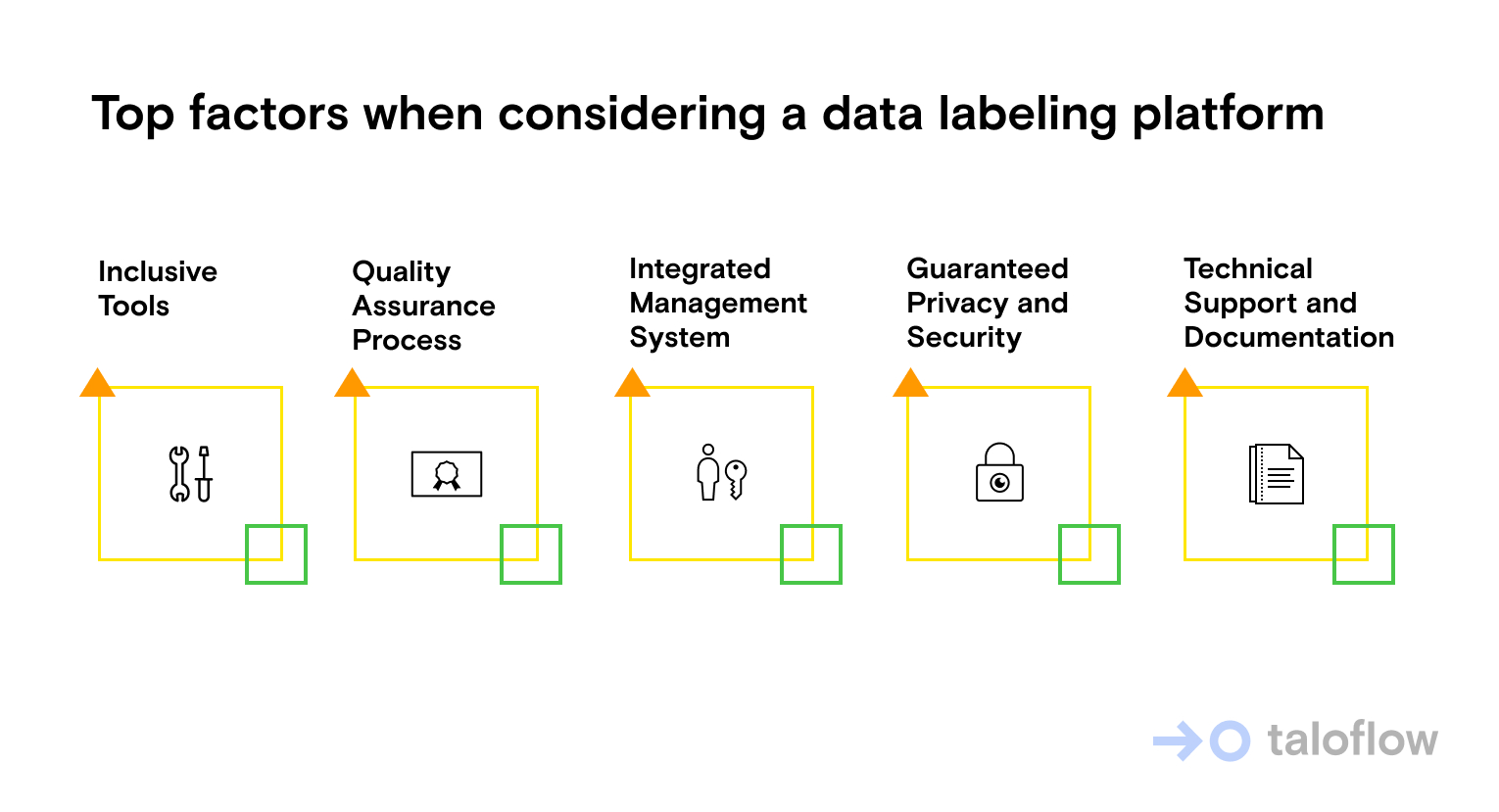
What to Look for in a Data Labeling Platform?
Below are some of the top factors to consider before choosing a data labeling platform:
Inclusive Tools
The right labeling platform will have all the tools you need to create the highest quality data labels. It's vital to emphasize that your choice of tool shouldn't only satisfy your current needs and be capable of meeting your anticipated needs. So, before settling for any platform, think a few steps ahead and consider the data sets you'll have to label in the future. You'll be saving time and resources if you don't have to switch to a new platform every time you have to work with new data sets.
Integrated Management System
Your data platform of choice should have an integrated management system that would facilitate managing data, users, and projects in one place. Such robustness allows project managers to monitor progress, track workers' productivity, implement data labeling workflows, monitor quality assurance, and perform other necessary tasks. Using a separate platform for any of these tasks could affect communication flow and the project's execution speed.
Quality Assurance Process
Your label platform should be equipped with a quality assurance process that affords complete control over the quality of the output. Remember, the performance of your ML models hinges on the quality of labeled data. Thus, the platform's quality assurance process should be one of your foremost considerations.
Guaranteed Privacy and Security
Data labeling requires feeding mammoth amounts of unlabeled data into the labeling platform. As much as you care about the output quality, the privacy and security of the data should not be compromised. Whether you're dealing with sensitive or seemingly innocuous data, you should always choose a platform that guarantees the privacy and security of your data.
Technical Support and Documentation
As always, you'll do better with a data labeling platform that has an active support team. The team should be ready to address issues as soon as they come up, ensuring there's minimal disruption to your workflow.
Examples of Data Labeling Tools
Here are some of the top tools you can consider for your next data labeling project:
Scale.ai
Scale.ai is a data labeling tool that helps annotate large volumes of manual data at high throughput. The platform seamlessly handles image annotation, NLP, 3D sensors, video data, and there's an automated QA system that ensures high-quality output for the most sensitive applications.
Key benefits:
Active learning and advanced querying allow you to choose what data to label.
The human-in-the-loop review ensures high-quality data and low latency.
Full API integration
Labelbox
Labelbox promises to help you save time by providing a single platform for managing your processes, people, and training data. This data labeling solution facilitates the interaction cycles between model training and data labeling. Thus, you'll have the opportunity to use your training data to improve your model and model to improve training data.
Key benefits:
Facilitates swift and seamless communication among all members of the project team.
Iterates processes to create improved datasets and make data labeling more accurate.
Offers a centralized center for easy collaboration.
AWS SageMaker Ground Truth
Amazon SageMaker Ground Truth is a fully managed data labeling service platform that automates training data for machine learning. The platform has a built-in workflow that facilitates speedy and accurate data labeling. It's versatile enough to handle all kinds of datasets, including text, video, audio, images, and 3D point clouds.
Key benefits:
It's fully automated and easy to master
Impressive quality control and data labeling accuracy
Possesses numerous labeling features that help you save time
Encord
Encord employs a novel micro-model approach to automate data annotation and deliver high-quality results. The platform also possesses a suite of powerful tools that eases collaboration across the project team.
From the web app that eases data annotation, classification, segmentation, and QA to the automation API that allows you to automate virtually every step of the labeling process to Python SDK that helps train models and process data, you can rest assured this platform has everything you need to make your labeling project successful.
Key benefits:
Embedded algorithms help to replace manual labeling
One-click top-of-the-line model training
Advanced visualization features to help discover imbalances and biases
Note: Cord is best suited for medical imaging and other use cases related to healthcare today.
V7
V7 is an all-in-one training data platform combining image annotation & video annotation, dataset management, and autoML model training to automatically complete labeling tasks faster and with less hassle. V7 enables teams to store, manage, annotate, and automate their data annotation workflows. It offers both paid and a free plan for education and works with images, videos, DICOM medical data, microscopy images, PDFs/docs, and 3D volumetric data.
Key benefits:
Automated annotation features without prior training needed
Composable workflows allowing multiple models and human in the loop stages
Real-time collaboration and fluid UX
CVAT (Computer Vision Annotation Tool)
CVAT (Computer Vision Annotation Tool) is an open-source and web-based tool (supported/maintained by Intel), and one of the most popular free image and video annotation tools that you can use to label your data. CVAT is used for labeling data for solving computer vision tasks such as: Image Classification, Object Detection & Tracking, Image Segmentation, or Pose Estimation. It supports multiple annotation formats including YOLO, Pascal VOC, or MS COCO.
Key benefits:
Can be used online and on your local machine
Easy to deploy—CVAT can be installed in the local network using Docker, but must be maintained as it scales
Comes with semi-automatic annotation
How To Use a Data Labeling Platform
It's common knowledge that the ideal data labeling platform should be user-friendly and break down complex tasks into micro-components. Still, many project managers struggle to choose the right data labeling platform for their needs. Below we highlight the critical steps to follow when selecting the best data labeling platform for your needs:
Choose the Best Tool for Your Use Case
Different data labeling tools may have varying annotation capabilities. While some tools may be perfect for image labeling, they may fall short when it's time to work with audio or video files. Aside from the annotation capabilities, you would also want to consider data security certifications, Quality Assurance requirements, storage options, and labeling features such as polygon, bounding box, etc.
Ultimately, the ideal platform should be able to satisfy your current and anticipated needs. However, with the diverse options available, it’s challenging and time-consuming to assess the pros and cons of each platform before arriving at a decision. That's why you could use a service like Taloflow. All you have to do is articulate your use case, and our experts will provide recommendations that will seamlessly fit your needs - free of charge.
Compare the Benefits of Build vs. Buy
Some companies have the in-house capability to build their custom data labeling platform. A custom tool gives you more control, guarantees security, and is not subject to pricing changes. However, this doesn't always make building better than buying. The main downside of building is that custom tools leave no room for evolution. They're usually not flexible enough to accommodate changes in your annotation requirements, and they may become redundant in the long run.
If your company is growing and you anticipate that your data labeling needs may change with time, buying may be the smarter option. Moreover, buying an enterprise-ready tool allows you to start the project immediately while accessing the latest technologies and third-party support.
Consider Your Organization's Size and Growth Stage
Scaling companies or companies already operating at scale will naturally have different requirements from an early-stage company. Working with an open-source labeling platform while crowdsourcing labelers is the cheaper and more popular option for early-stage companies. However, crowdsourcing prevents you from establishing process stability since you can't work with the same team for a long time. This consequently affects the context and quality of your labeled data. If you have the resources, it's more advantageous to work with a reliable workforce vendor.
Consider Your Data Quality Requirements
Although most platforms have automated QA features, you still need people to perform quality assurance tests on your work. This is because the acceptable error rate for the software may not be well below your required confidence threshold. For example, OCR software typically has an error rate between 97 to 99% per character. While this may be acceptable for a few pages, the error margin becomes too much when labeling an entire book. Skilled labelers with domain expertise can help you execute another QA layer that ensures the number of errors remains within the acceptable standards for your project.
Best practices for Data Labeling
Data labeling is typically time-consuming and resource-intensive. However, following these tips can make your task easier:
Create a solid tagging taxonomy that's unique to your business
Creating a solid taxonomy allows you to categorize your data across multiple channels and sources, thereby streamlining the labeling task. You can either use a flat taxonomy or hierarchical taxonomy depending on the nature of your business and the volume of data you're working with. While a flat taxonomy is suitable for companies with low-volume data, hierarchical taxonomy works well for companies with high-volume data or that operate in multiple industries.
Keep tags to a maximum of 10
Not having more than ten tags gives your annotators enough time to intimate themselves with each tag and its definitions. Consequently, there'll be less room for confusion or crossover as the task progresses. You may even increase the number of tags as necessary over time. But it's always better to start with ten tags or less.
Determine the granularity of data
The granularity of your data directly influences the complexity of your taxonomy. Thus, your annotators should know whether they're analyzing whole documents, paragraphs, sentences, or websites.
Choose representatives who are experts in the field
Businesses operating in the same industry are likely to have similar datasets. If you can get labelers who've previously worked in your industry or on similar projects, you're more likely to get higher-quality training datasets.
QA test your taxonomy
Before embarking on the labeling proper, there should be a QA test that verifies that your taxonomy is appropriate for the defined purpose. You should also ensure that the human labelers do not deviate away from the preset requirements.
Create an annotation handbook
An annotation handbook helps you define your tagging criteria. The handbook will include concise examples of correct, incorrect, and edge labeling and would serve as a guide for your human labelers.
Collect diverse data
Diverse data collection is the precursor to developing machine learning solutions. The better the quality and diversity of your input data, the more effective your training data.
Find The Right Data Labeling Tool With Taloflow
It's a well-known fact that the performance of your AI model greatly hinges on the quality of the data employed in training it. But getting high-quality training data requires the collaboration of both humans and data labeling software. So, even if you have the best team, you can only get the desired level of precision, consistency, and accuracy with your training data if they work with the right labeling tool.
At Taloflow, we have expert data scientists and engineers that have worked with various data labeling tools, and we can help you decide the best option(s) for your specific use case. Digital natives across all industries trust our recommendations, and you can rest assured we'll arm you with all you need to make an informed decision. Whether you're looking for recommendations within a specific category or you want to check if the tool you're considering will be a good fit or you're looking for an upgrade on the current tool you're working with, you can always rely on the experts at Taloflow for the best recommendations. Contact us at [email protected] to start a discussion.
Conclusion
Data labeling or annotation is as old as machine learning itself. Before automation and diverse labeling tools, humans devoted time and energy to manually labeling data points. This method was highly time-consuming and error-prone, rendering it inefficient.
Today, state-of-the-art data labeling tools allow humans and machines to collaborate and deliver precise and efficient data for various ML applications. Combining the right tools and technical expertise is the key to extracting high-quality training data from your raw data inputs.
Editor's Note: This post was originally published on September 1st, 2021 and has been updated to include new vendors for completeness.
Related posts
Here are some more posts from Taloflow and its community that are related to this topic.
By clicking “Accept All Cookies”, you agree to the storing of cookies on your device to enhance site navigation, analyze site usage and assist in our marketing efforts. More info
By clicking “Accept All Cookies”, you agree to the storing of cookies on your device to enhance site navigation, analyze site usage and assist in our marketing efforts. More info