Handling LLM Hallucinations: Taking Your LLM Features From Prototype to Production
LLMs are bound to perform unexpectedly, and this post will cover various manual approaches, generative AI development frameworks, and more to address this.
Co-founder at Lytix
Sahil is the Co-founder of Lytix, a Y Combinator-backed company that helps you include text analysis in your product analytics, and triage bugs in order to reduce LLM hallucinations.
Since ChatGPT was released in 2022, developers have been eager to bring the power of LLMs to their own products. It’s typically easy enough to whip up a proof of concept that one can use on their local machine, and these prototypes work well enough with a small number of cases.
However, when developers take these features live, they encounter a whole host of problems they were not expecting. With enough users hitting your product and using it in unexpected ways, LLMs are bound to perform unexpectedly. Your users may hit errors you haven’t seen before, or have a subpar product experience because of an edge-case you weren’t aware of. Unfortunately, tooling to solve these problems have not developed as fast as the LLMs themselves have. This leaves developers scratching their heads, thinking of ways to keep tabs on their users’ experience.
Lytix just went through Y Combinator's Winter 2024 batch, where over half the companies were building on AI. We’ve written this post based on our experience learning from and working with companies on the frontlines of building and scaling AI-based products.
What are LLM Hallucinations?
Below, we'll cover a few ways to think about and diagnose LLM “Hallucinations”.
In the most direct sense, hallucinations are responses from LLMs that are factually inaccurate. Depending on the model and subject matter, LLMs can hallucinate anywhere from 3% to 25% of the time.
However, in a broader sense, we can think about hallucinations as the LLM providing responses that ignore user or system instructions.
Responses that breach guidelines or guardrails (i.e., “as a Large Language Model I cannot provide legal, health, insurance, etc. advice")
Unfortunately, handling these errors is not easy as in the pre-LLM world. There are no unit tests one can run to see if your latest change produces more or less hallucinations. Traditional error or crash alerts are also not reliable at catching these kinds of LLM behaviors.
Current Approaches to Handle LLM Hallucinations
So what do teams do today? In our research, we found that there are two approaches that teams have converged on.
1. Manual Logging
Manually logging as much as possible, and reviewing these logs manually is the first approach.
For chatbots, this might be logging each input from your users, and output from your bots, and stitching together conversations manually.
For search-based tools, this might be receiving a report of each user query, what went on behind the scenes, and the final output.
The downsides of this approach obvious. Ideally, you wouldn’t sink hours into manually reviewing each of your users’ product sessions. And as your user base increases, this becomes unscalable. Furthermore, it’s also prone to user error: how do you know you haven’t missed an interaction that might warrant more attention?
2. User Reports
Relying on users to report errors as they find them is the second approach. On paper, this has the advantage of being slightly more scalable as you simply review the errors your users have reported. In practice, teams are moving away from this for a few reasons:
Ideally, you would catch an error before it reaches the user, so you can handle it gracefully, and maintain a better user experience.
In our experience, users report very few errors, and in most cases, they just stop using your product or gradually use it less when they encounter frustrating hallucinations. Therefore, relying on user reports means you’re necessarily seeing a small percent of the total errors your user-base is facing.
Given this, you're probably wondering if there are any useful tools for reliably and gracefully handling LLM errors.
Development Frameworks for Generative AI
Building your generate AI features through a development framework can help limit the number of errors you’ll face. Frameworks are also beginner-friendly ways to get started with LLMs.
Frameworks can help reduce hallucinations in a few ways:
Built-in observability
Typically, these platforms have built-in observability and evaluation tools. These can help you keep tabs on what your LLMs are doing, and can assess each output against a set of vetted metrics. Vellum, for example, gives developers metrics like semantic similarity (is the LLM output similar in meaning to a given ‘target’ or ground truth?), and JSON Validity (to confirm the LLM output matches a predefined shape). This can help you identify what kinds of errors your users are facing most frequently, and iterate accordingly.
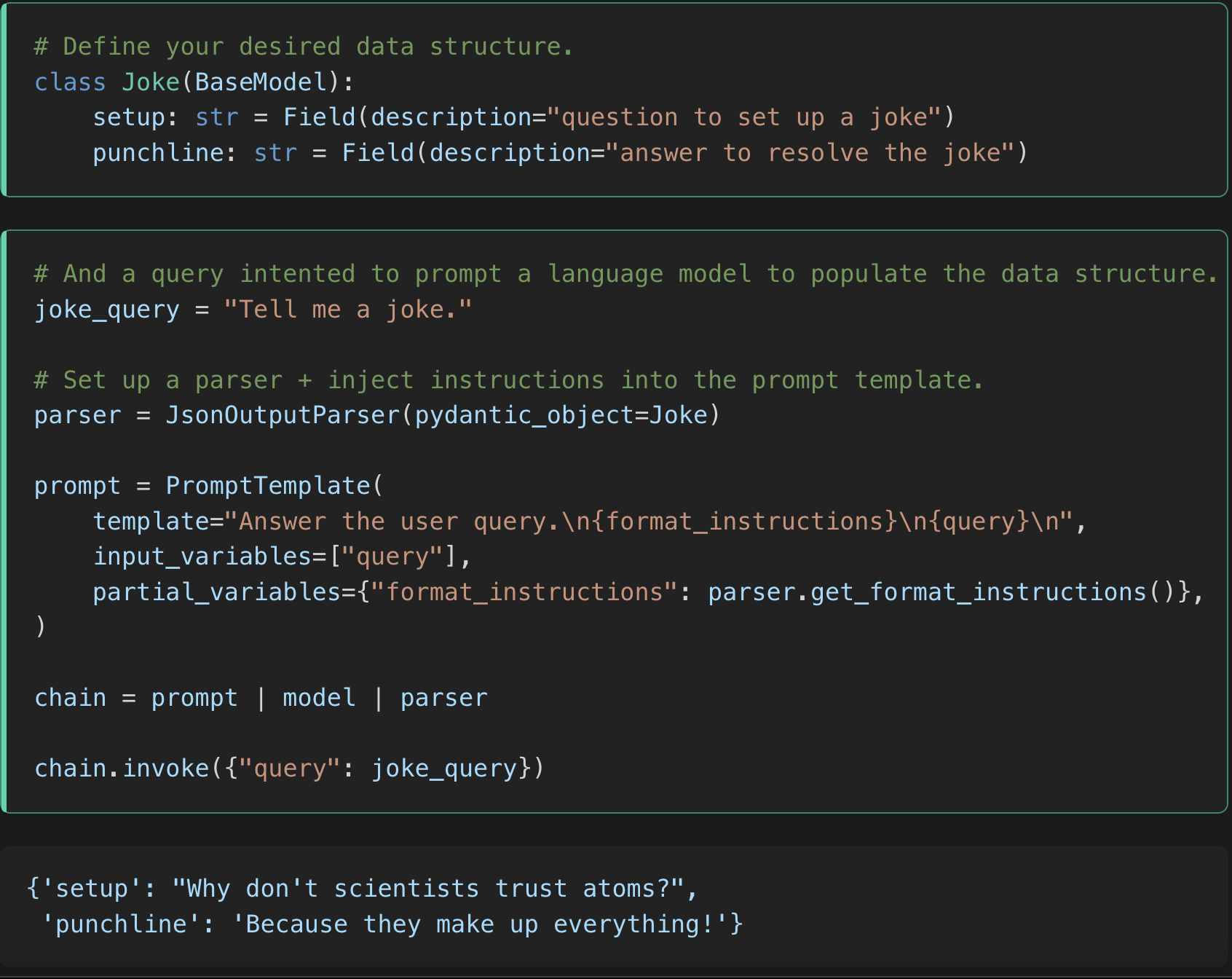
Reliable output parsing
You may need your LLM to return a response in a particular format, (e.g., JSON, CSV files, Pandas DataFrames) based on how you’re handling the response downstream. In theory, this should be as simple as asking your LLM to "return the response in (your desired format)". In practice, we see that getting your LLMs to do this reliably takes some seriously savvy prompt engineering. As you use more of your context window, prompt engineering efficiency gets even more important.
Instead of wasting your time fiddling with prompts, platforms like LangChain let you use their output parsers right off-the-shelf while they handle all the prompt engineering under the hood. This can collapse 10-20 lines of code into just 3-4 lines with prompts that provide reliable results. These parsers often have embedded "retry" logic embedded, which will automatically re-attempt to parse the output if it sees an error. This lets developers focus on building great product, and not waste time trying to win an argument with an LLM.
Generative AI Development Framework Cons
While frameworks can be a great way to get your foot in the door, we’ve found developers quickly outgrow them as their needs evolve and get more complex. Developers may find themselves over-engineering their way around opinionated frameworks in order to get what they want. Folks who are familiar with working with LLMs may find frameworks to be too abstracted and awkward to work with.
Additionally, the base models are always expanding their tooling, reducing the need for certain framework features (for example, OpenAI now lets users receive their outputs as JSON objects of a particular shape).
The open-source community has built some very useful solutions that developers can use without using a development framework. These are machine-learning or LLM-powered techniques that provide metrics representing the quality of an LLMs output along a particular dimension. For example, the BLEU score (Bi-Lingual Evaluation Understudy), shows how grammatically and semantically coherent an LLMs output is. Similarly, the toxicity model on HuggingFace provides a numerical score representing how toxic a given response was.
Open-source evaluation tools can help developers in a couple ways:
Real-time checks to prevent users from ever seeing an undesirable experience. These libraries are often very flexible and easy to work with, so developers can bake them into their product experiences. For example, if an LLMs response is incoherent, you can instruct it to try again until the response has a strong BLEU score.
Augmenting existing custom dashboards with a custom set of metrics they care about. This can give your team an "observability platform", comparable to what you’d get with a development framework.
There are also open-source monitoring and evaluation platforms, which give developers many of these metrics right out of the box rather than manually configuring the ones you want. While some of these are not free, they may be worth the saved time.
While not as programmatic as some of the other approaches, simple Regex matching can help identify particular edge cases your product might care about, but may not be universal enough for the open source community to have built a solution for. We’ve seen developers get surprisingly far with simple RegEx functions, catching common phrases or words that represent failure cases.
For example, teams building in more regulated industries, such as health, insurance or law, may find that they frequently get LLM "refusals" (i.e., "as a large language model I cannot advise on legal/health related matters") due to safety guardrails. While manual, this can give you even more fine control over your users’ experience compared to what the open source evaluation tools can provide.
RegEx Matching Cons
RegEx is notoriously not easy to work with.
In the beginning, it may take several attempts to find the right strings to look for in order to find your failure cases
You’re still relying on manual logs or user reports to find the strings that represent failure cases. This means users will still hit failure cases you have not implemented RegEx matching for.
There’s no doubt that LLMs are a powerful addition to any developer toolkit. However, this is also a brand new space with very few best practices and tools to work with. While manually logging and reviewing your user sessions may work initially, you’ll find this quickly gets out of hand as the number of users and sessions increases. We hope these tips help developers bring their ideas to production faster and improve reliability.
If you're interested, we also wrote detailed post about self-hosting an LLM.
Finally, we'd love to see if Lytix can help you think through alerting for your LLM applications.
Related posts
Here are some more posts from Taloflow and its community that are related to this topic.
By clicking “Accept All Cookies”, you agree to the storing of cookies on your device to enhance site navigation, analyze site usage and assist in our marketing efforts. More info
By clicking “Accept All Cookies”, you agree to the storing of cookies on your device to enhance site navigation, analyze site usage and assist in our marketing efforts. More info