
Louis-Victor Jadavji (or "LV") is a recognized leader in the cloud services industry. He's helped 50+ digital native companies like ModusBox, Later, and NS1 choose the right cloud stack for their applications. His work has been featured in Forbes (30 Under 30 All-Star), HuffPost, The New York Times, The Globe and Mail, and Inc. Magazine.
Cloud object storage is a globally-accessible and scalable storage solution. It is best used for storing unstructured data, like images, documents, videos, and logs.
Since its early beginnings circa 2006, cloud object storage has been a convenient way to store large amounts of data. Over the years, it has evolved significantly to address the needs of complex, high-performance, and low-latency applications.
Note: Object storage is most commonly used as a cloud-based service, but on-premise solutions exist as well. Our write-up will emphasize cloud object storage.
Object storage can help facilitate many modern-day business use cases, such as:
In this article, we’re going to cover object storage in great detail. You’ll learn about:
Cloud object storage provides online businesses with numerous advantages. Some of these are:
One of the main selling points of cloud object storage is data redundancy. Redundant data storage results in a much lower likelihood of data loss.
Many vendors accomplish this by copying your data across multiple data centers and disks, and sometimes even across regions. Typically, if data loss is detected by the cloud provider, your files are automatically repaired.
Object storage solutions are very scalable. Unlike working with traditional disks that have set sizes, there’s essentially no limit to how much data you can store with your typical object storage provider, budget-permitting.
Products like Amazon S3, Azure Blob Storage, or Google Cloud Storage are tightly integrated with their other services. This gives developers the tools, like serverless functions, to integrate object storage with the rest of their cloud project.
For “Big Data” use cases, object storage provides quick and affordable reads and writes. Not only is it scalable, but it’s fast too. Object storage lets you store unstructured data in a manner that is easily indexable and retrievable for use, no matter how big your data lake becomes.
Store high-quality visuals (e.g.: images, videos, graphics) in large quantities that can be retrieved by your applications, website, and even store static pages as objects.
Object storage vendors offer low priced options for data backups. Data backups are typically rarely accessed or used.
Most vendors offer a storage class specifically for archival use that:
Amazon S3 Glacier (the “coldest” form of storage offered by AWS, as the name implies) is an object storage solution designed for archival purposes. Generally, archival storage comes with dirt cheap pricing, but with slow or limited access to data. AWS claims that Glacier has 99.999999999% data durability. For use cases requiring faster access to data, AWS and other providers usually let you configure your access speeds.
Google offers a similar, archival-specific storage class called Archive. This offers the best rates on GCP for data you’ll need to access less than once a year. If you need that data a bit more frequently, the Coldline storage class may be more suitable.
Other notable offerings for archive are:
For a pricing comparison of archive storage providers, click here.
Cloud object storage is usually provided as a managed service. This means that the vendor will take care of the technical stuff like adjusting RAID levels and dealing with logical volumes to maximize disk capacity.
Cloud object storage can optimize business needs and costs. However, in some scenarios, it can be the wrong choice. We expand on this in the sections below.
Structured data is anything that can be arranged in a tabular order, like in a CSV file. If your data is “structured” it’s quite likely that a traditional relational database is a better fit.
Once an object is uploaded to a bucket, it can’t be modified (exception: Azure is unique in offering append blob, a way to modify an existing object by adding onto it.). The entire object has to be replaced.
So if you’re working with data that is frequently changed, you’ll need to repeat these steps every time you need to amend your data:
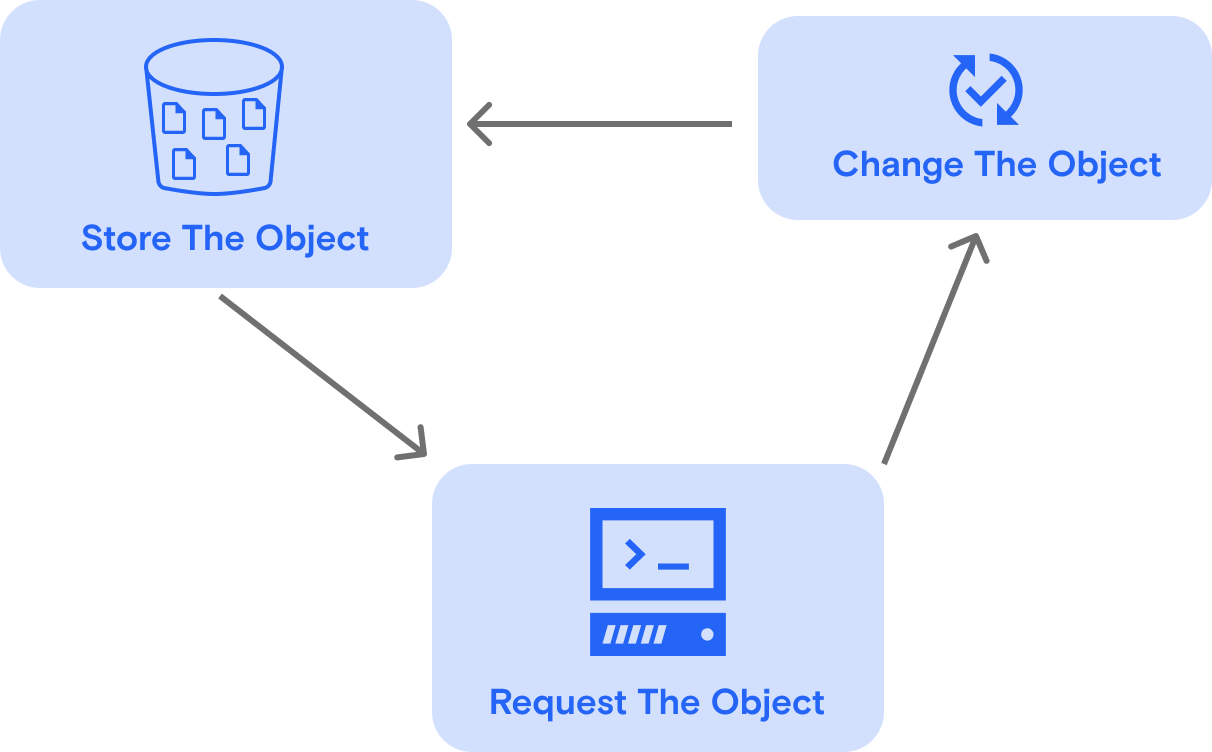
Even if you change a single character in a file, you’ll need to go through these steps. Aside from the time it takes, reads and writes to storage will usually cost you money. So for this kind of data, it’s better to avoid using object storage.
Object storage is not the best choice for applications that need to quickly save, access, or change files. Block or file storage is better, which we cover below.
Objects can be any kind of file, like a video, image, or even an Excel or Word document. When the user uploads this file to a bucket, the file becomes an object.
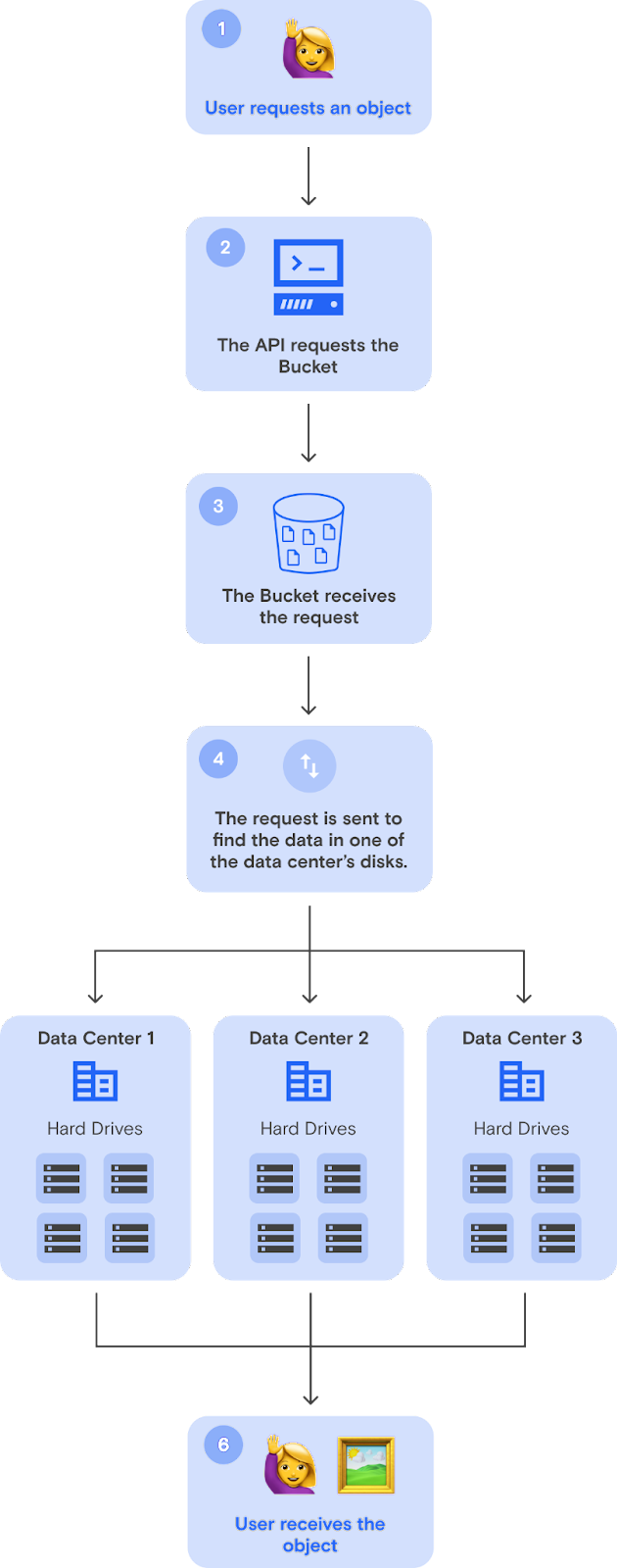
An object that is uploaded to a bucket is then replicated across a number of physical storage devices. These hard drives can exist in a single data center or be spread around multiple data centers.
Once an object is uploaded, the user interacts with it through an API. The illustration below shows what interacting with objects looks like.

Data you need fast access to is stored in “hot” storage.

Data in the middle is stored in “infrequent access” and some types of “archive” storage.

Data accessed the least is stored in “cold” or “deep archive” storage.
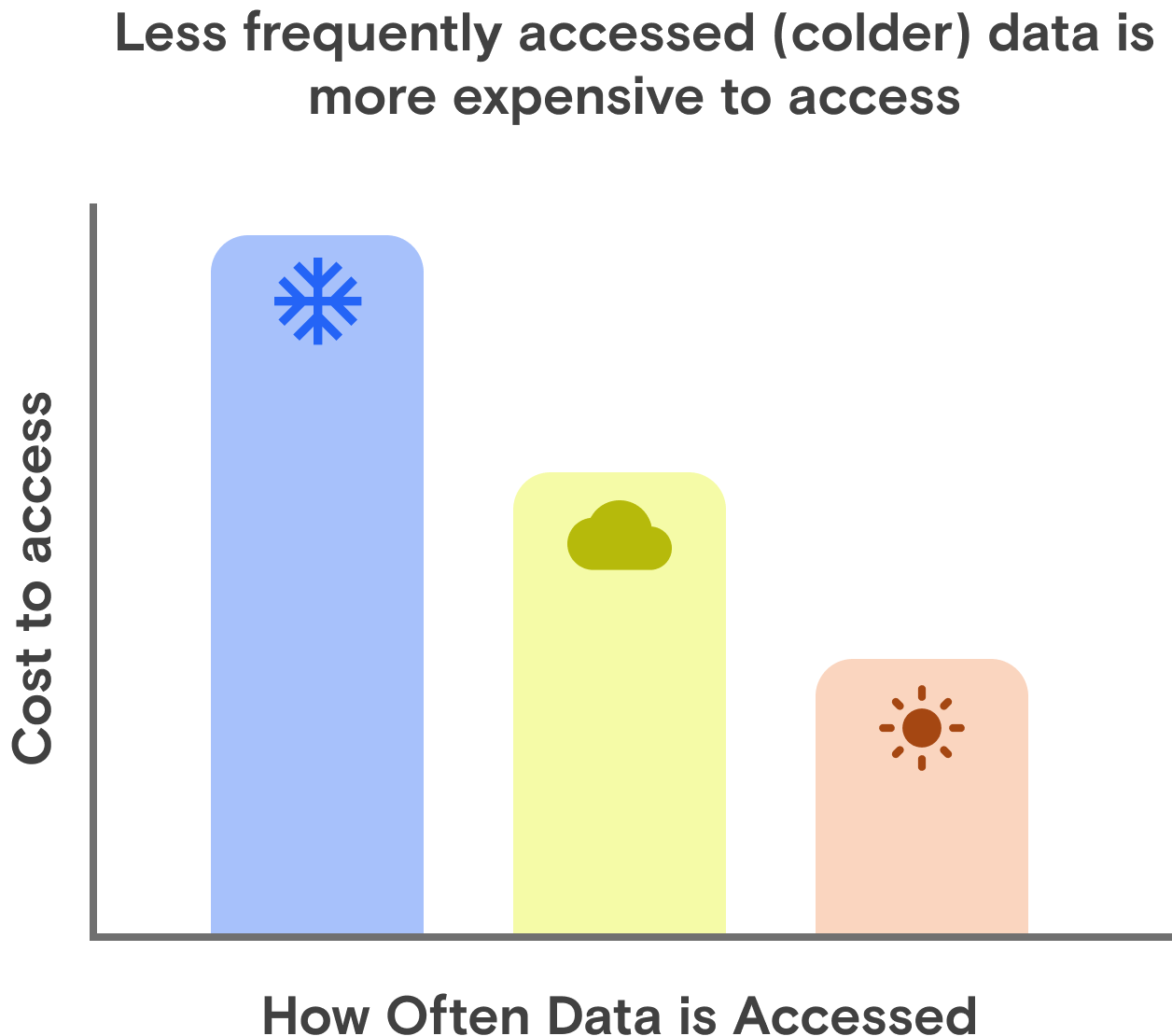
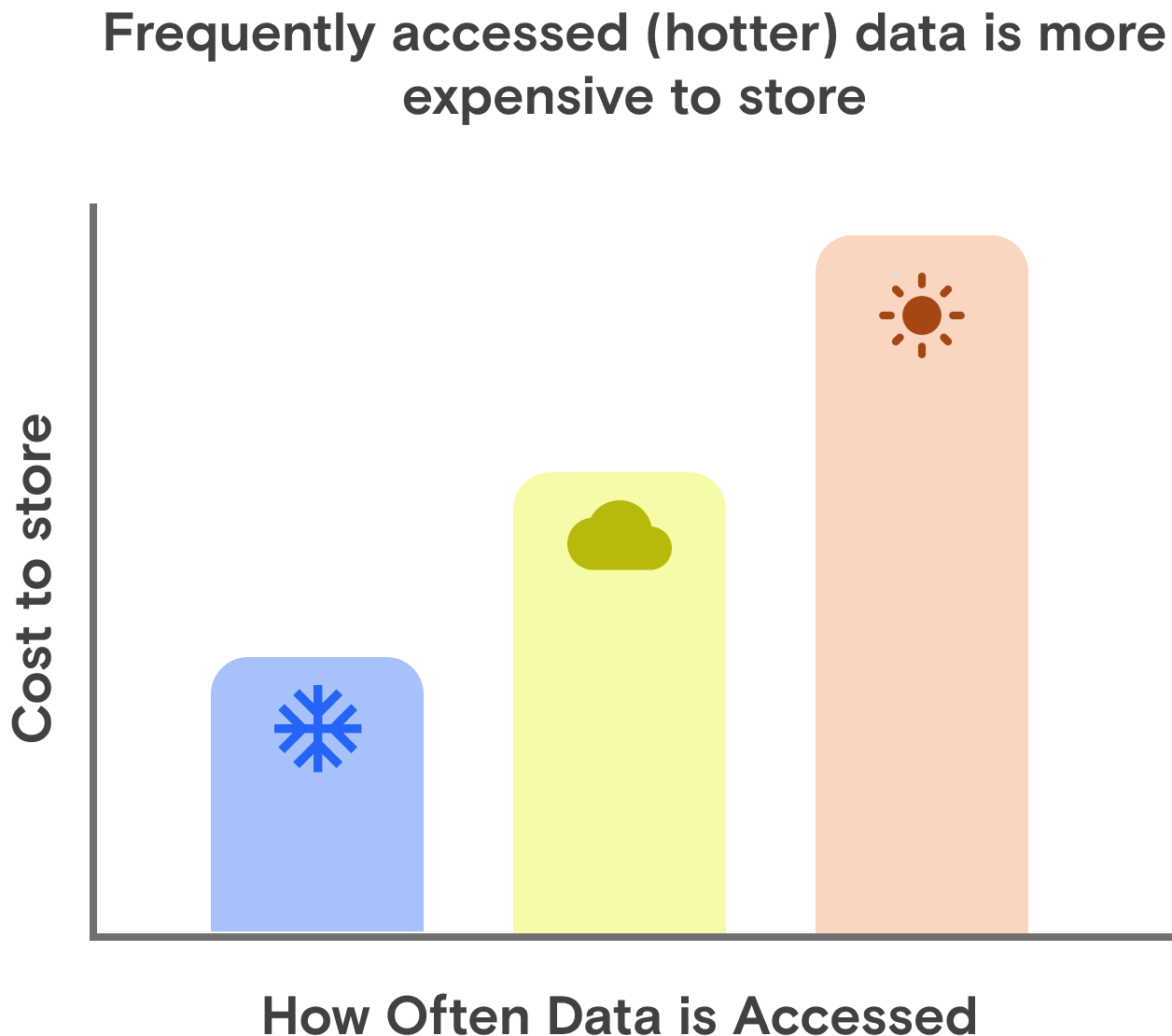
The cost of interacting with objects depends on your use case.
If you’re hosting the assets for your website, you need frequent and rapid access to your files. However, the most expensive tiers for cloud object storage have frequent and rapid access to data enabled.
Infrequent Access (IA) tiers balance cost and accessibility. They offer faster access than pure archival tiers but have more expensive data retrieval costs than frequent access tiers. If your data isn’t accessed too frequently but is needed quickly, this can be a way to save some money.
Archival storage tiers usually have data retention policies of up to six months or longer. This means that when you upload data, you’re committing to it being stored for a minimum period of time unless you want to pay additional fees or penalties. Archival tiers offer the lowest storage pricing with the trade-off of having to pay the most to access it without restriction.
Check out our complete object storage pricing guide here.
Storing files is a means to an end. Object storage services are tightly integrated with other specialized services to accomplish common tasks described below.
When storing unstructured data for later analysis, object storage is a common destination. Some of the more popular tools to analyze this data are:
Object storage is a common backend for machine learning data. Popular AI platforms that integrate with object storage providers are:
It’s cost-effective and more performant to use a CDN to manage serving files to end users.
Popular CDNs include:
Cloud object storage vendors tend to specialize in different areas. We’ve published an overview of all cloud object storage features here.
Our research shows that no single vendor covers all the specialized use cases out there. If it’s amazing for one use case, the vendor most definitely makes compromises elsewhere.
The three most important considerations when choosing your cloud storage vendor are:
Depending on how your application accesses data, the cost of object storage can vary wildly. The main cost components are:
We have a pricing comparison guide you can review here.
Amazon pioneered the cloud object storage format in 2006 and named it Simple Storage Service (S3). Since then, other cloud vendors have strived to build their own storage services to be interoperable with S3.
Important note: Vendors that say they have an S3 compatible API may not have a fully-featured version of the S3 API.
A strong selling point of object storage is the ability to make your data redundant by replicating it across multiple storage devices, data centers, and regions. You lower the likelihood of data loss due to things like device failures with every additional replication.
Most cloud storage vendors offer storage in 3 formats:
We’ll look at the fundamental differences between the three types of storage. If you’re familiar with file storage and just want a use case comparison between the other two, you can view our detailed comparison of block storage vs object storage.
One fundamental problem that cloud object storage solves is abstracting away the idea of disks. This means that low-level disk management issues, like running out of space, are no longer your concern. Objects are categorized and secured in a robust way through access control policies and metadata. Your data is stored with the following:

These add-ons to the files solve retrieval and security challenges that most developers face. Object storage is great for redundant, scalable data. For high performance and throughput, file and block storage may be better options.
File storage is the intuitive format we’re all accustomed to using on our computers. The files are arranged in a logical, hierarchical structure that can be accessed by knowing the exact path to the file. This storage system has been around for decades and is still widely used today. Very limited metadata is required to access files when you’re working with file storage.
File storage is best suited for working with small amounts of data neatly stored on a disk. The main drawback of file storage is its limited scalability given it requires more hardware to be put in place.

In block storage, data is broken down into small parts put into different parts of the storage device. These parts are of a fixed size and are called “blocks”. A portion of a file can exist in one block, and the rest can exist in another.
This method allows the system to optimally break down data into tiny pieces and arrange them in different blocks, allowing the whole disk to be utilized. The blocks have an identifying number which allows the required blocks to be reassembled upon request.

Block storage is primarily used in storage area networks (SANs). Servers are installed in the network which handle all data read and write requests.
Applications that require very low latency to work are a good use case for block storage. Block storage also provides data redundancy by design, so you don’t have to worry as much about managing backups. Databases can also be easily stored in block storage.
Block storage can get very expensive to maintain. It also doesn’t provide the same metadata capabilities as object storage. This forces developers to work on the metadata themselves when they are designing applications.
Ransomware is a type of cyber attack in which all your files get encrypted by a malicious party. Since they hold the keys to decrypt your data, the only way to get your data is to pay them (i.e., a “ransom”) . If you don’t pay the attackers, you might permanently lose access to your data unless you have it backed up elsewhere.
Ransomware originated in the 1980s and has since evolved a fair bit. In fact, the average ransom price increased 4000% between 2018 and 2020.
If you’re using object storage, you might be wondering how to best protect yourself from ransomware.
While object storage has built-in mechanisms to secure your data, some storage vendors take security to the next level.
Wasabi provides data immutability. This means that your data can never be deleted by any entity, including Wasabi. Wasabi storage buckets allow you to configure them to be immutable for a specific time period. They can be further tweaked to be deleted after a certain time has passed. Wasabi claims that bucket data cannot be altered or deleted for as long as the bucket exists. This also applies to ransomware attacks as they cannot encrypt the data.
Storj takes a different approach to data security. Instead of immutability, they spread the user’s data around a much larger storage area comprising 13,000+ globally-distributed nodes. Each file is stored on 80 different nodes, with only 29 online nodes needed to retrieve the file. Their approach is considered to be safer by “default” against very specific kinds of ransomware attacks wherein the attacker manages to breach the cloud provider.
The fastest way to find a vendor that does exactly what you need it is to take our 5-minute questionnaire. Everything we covered here and more is taken into account when creating your recommendation.
If you're looking to do more reading, we've got a few relevant resources:

