
Taloflow is your all-in-one solution to automate the heavy lifting of research, comparisons, and reporting for consulting teams enabling enterprise procurement and deal strategy.
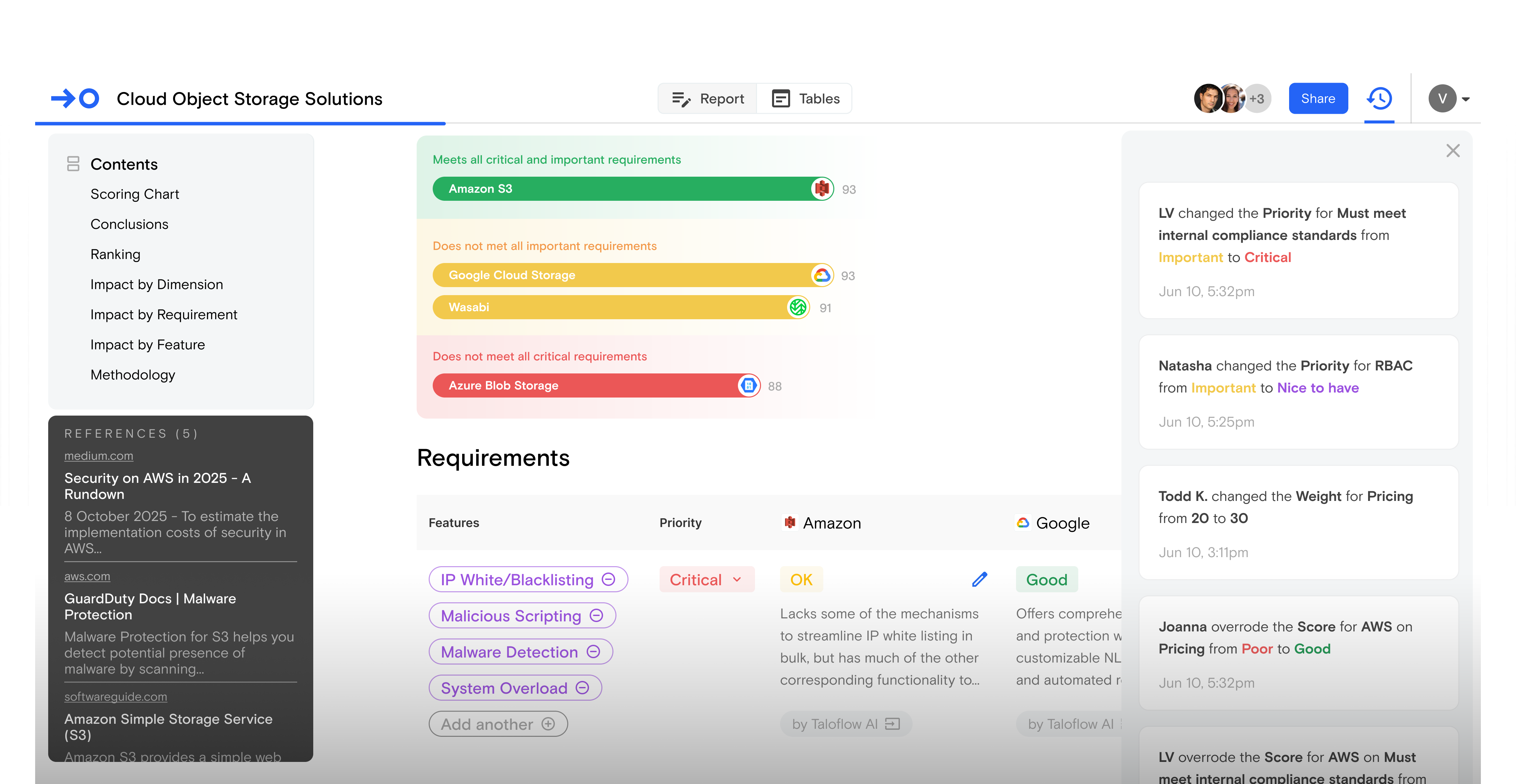
Taloflow helps define your use case, and run a comparative vendor selection process without a time-intensive discovery.
Quickly understand the detailed feature functionality of different products as it relates to specific use cases.
Less Work. Reduce desk research and quickly achieve feature capability understanding.
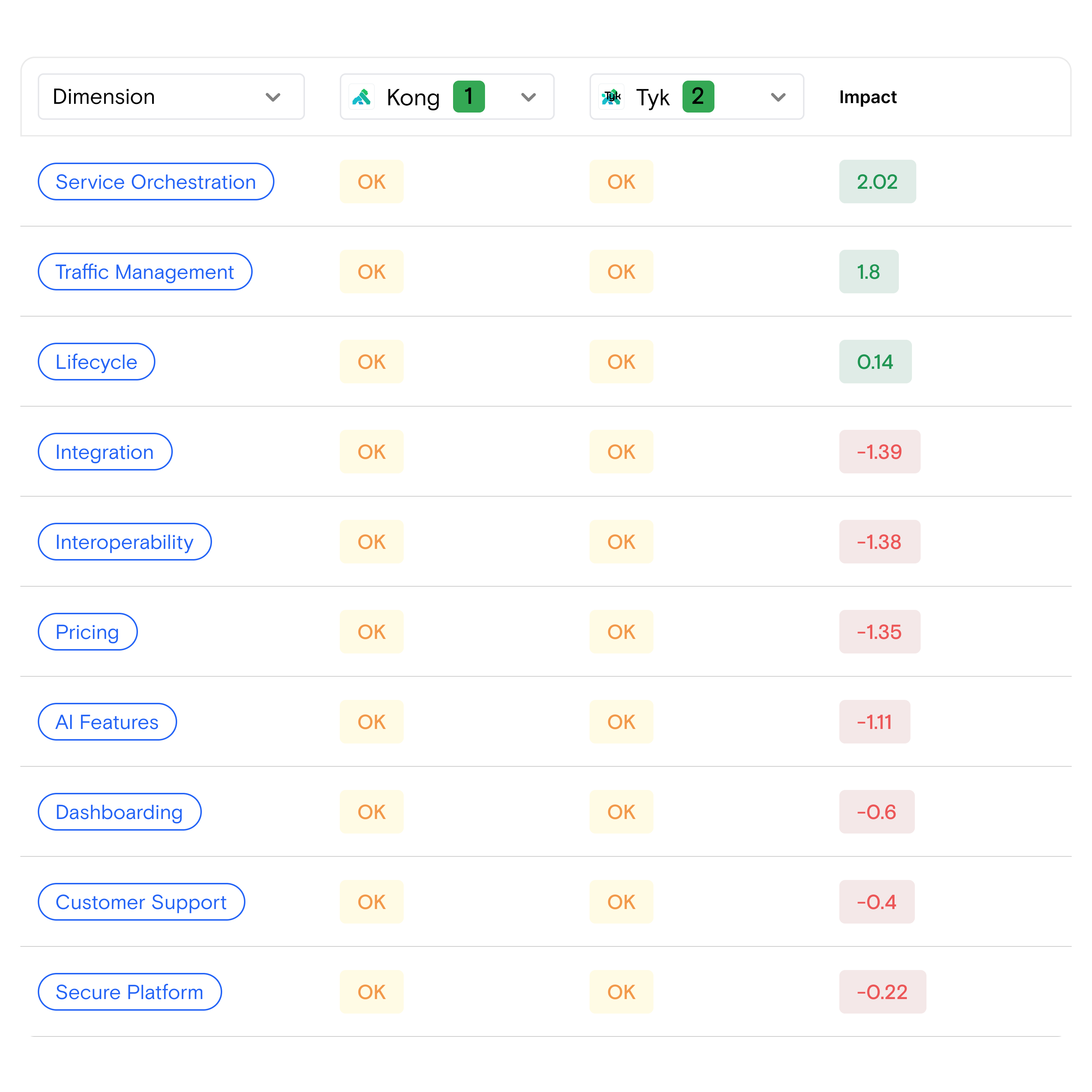
Built-in Data. Access to carefully-curated proprietary and public alternative data sets.

Know What Matters. Improve speed to insight and confidence around differentiation.

Expand the reach and speed of your services with detailed, customized requirements and vendor evaluation reports that match your client's unique market assessment needs.

Automate vendor discovery and comparison
Access curated and updated data sets
Collaborate in real time across analysts
Generate branded client reports in minutes
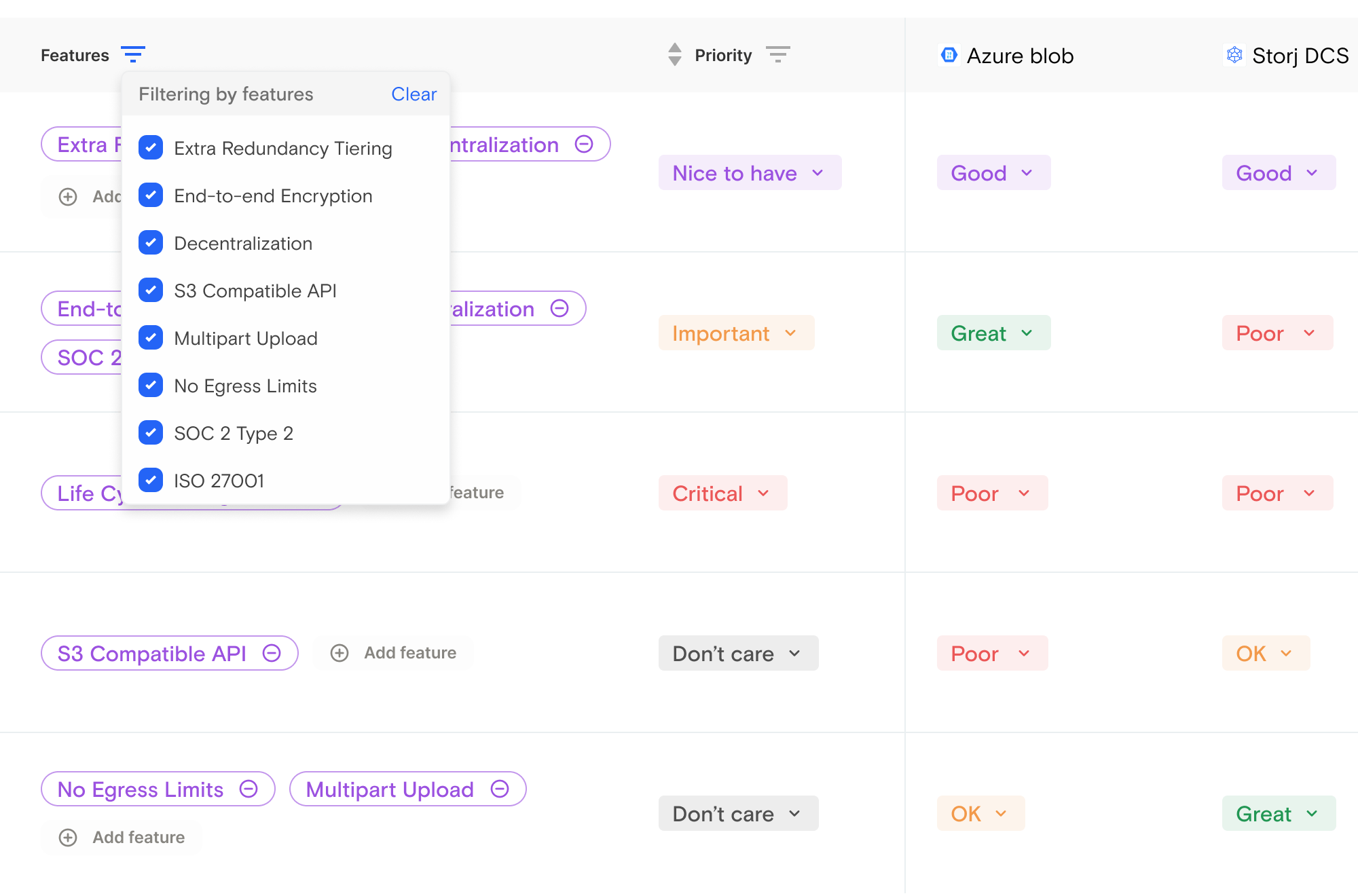
Use Taloflow to spend less time gathering data and more time shaping client strategy.
Faster research cycles
Less manual research
Number of vendors
More detailed
Get your ROI in under one day
Faster Research
Tailored Insights
Seamless Collaboration
Data Exports
Secure, audit-ready, role-based access so your technology evaluation process can scale across thousands of stakeholders.

Role based access control to assign appropriate permissions based on team member responsibilities.

Organizations and workspaces to make it easy to manage and access relevant data and resources.

Clear audit trails to ensure that all updates and modifications are transparent and documented.
Get a transparent client-ready report tailored to your client's unique use case and requirements.





